20140403
关于线性回归和逻辑回归
线性回归是用于拟合数据的,也就是用于prediction,如果用它做classification(加一个threshold二分类),效果会很不好。逻辑回归一般是用来做classification的,也可以这样说,逻辑回归是对某个样本是正样本的概率进行了prediction,这个prediction我们再加上一个threshold做二分类,就变成了classification。
线性回归的cost函数直接用最小二乘就是一个凸函数了,而逻辑回归用最小二乘作为cost的话函数是非凸的,大概长这个样子:
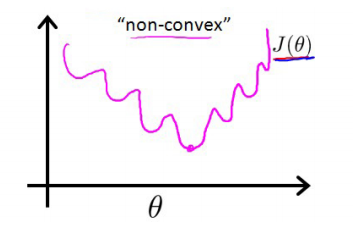
于是引入了另外的cost function: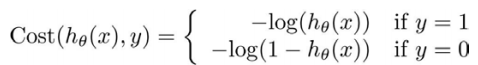 这样子cost函数就会变成凸函数了,就能够用梯度下降求到最优解了。
这样子cost函数就会变成凸函数了,就能够用梯度下降求到最优解了。- 下面讲了优化算法除了梯度下降还有其他conjugate gradient,BFGS之类,这些算法不需要自己设置学习率,而且速度一般比梯度下降要快。但实现较为复杂,可以直接调用matlab的优化函数。
- 虽然线性回归用的MSE和逻辑回归用的MLE在cost function上形式差别比较大,但是求导之后的形式倒是一样的(其中
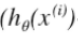 的定义不一样,前者是wx,后者是wx+sigmoid),都是:
的定义不一样,前者是wx,后者是wx+sigmoid),都是:
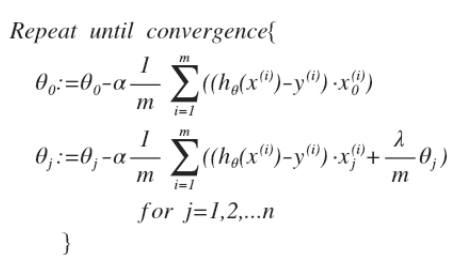
20140403
今天提交作业2,100分~
不过中间尝试的时候做错过一次,是计算regularized logistic
regression时候的cost function,最后的regularize
term的theta平方相加的时候,是不用加上theta0的。
\
20140408
今天一口气将week4都看完了,因为week4和week5讲的是神经网络,这个已经很熟悉了。
一开始讲了为什么要引入神经网络这个非线性的分类器。用线性回归和逻辑回归也能够解决部分的非线性问题,他们是通过将特征映射到高维的区间上来进行分类的(这个跟SVM的假设是一致的,认为高维之后的特征向量可能就能够线性可分了)。
但这样也带来一个问题就是特征空间会O(n\^2)(映射到二维的情况)地增长,100个特征映射到5000维,如果是映射到三维,那么就更加恐怖了。特征过多会带来过拟合的问题。
于是引入了神经网络这个非线性的分类器来解决问题,中间还用了直觉的例子来说明神经网络是怎么通过级联线性单元来表示非线性的函数的。就是下图的经典XOR分类问题。
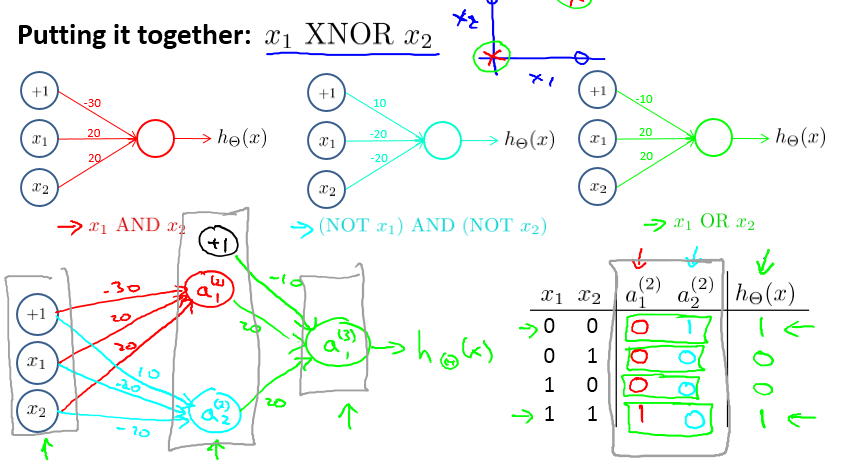
其实简单来说,可以把神经网络看成是一个特征组合(特征表示,feature
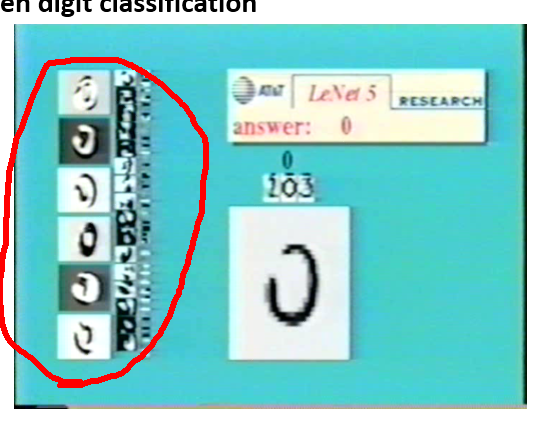
representation)的过程,对于每个隐层,都是一次特征重新组合的过程,通过神经网络训练出来了一种特征组合的表示方式。(这个跟我们开seminar时候讲的道理是一致的)。LeNet的例子就很能说明这个问题:
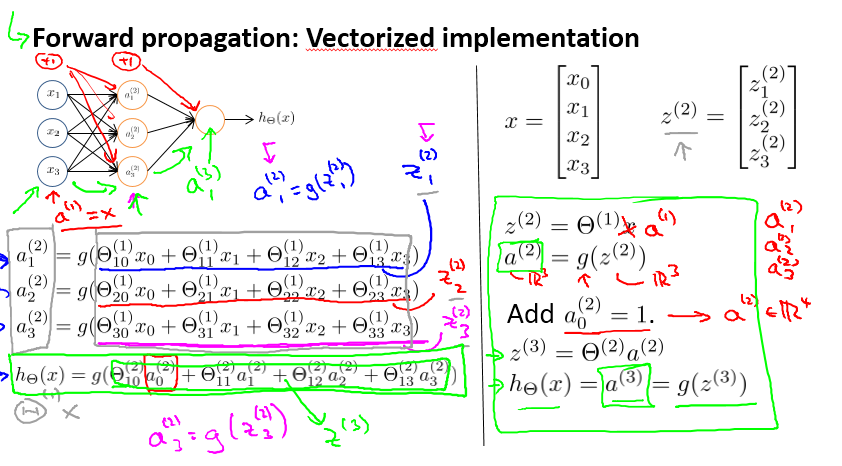
又及,神经网络的公式也可以用向量的形式来表示,确实简洁多了。
\
20140414
今天看了Week5 learning ANN的其中一部分。
总结下收获:
LS和MLE在高斯噪声下是等价的:在线性回归的时候就发现了LS和MLE最后得到的cost function虽然形式是不同的,但是对他们进行求导之后,形式却是一样的。之前Seminar时候亚龙讲ANN时候,也提到了ANN有MAP和MLE两种形式,但后面MLE自动就变成了LS了。从求导的意义上来讲,它们两个却是是等价的。
Andrew的cost function里面多了一个regular term,跟Mitchell书上的公式貌似不太一样,最后差别貌似最后更新时候,bias term的更新会少了一个更新(λ*weight),具体起来还有会其他的差别吗?这个留作一个疑问吧。
ANN的计算过程却是比较复杂,当时上李蕾老师课时候实现就出了bug,后来是重写了一次才正确了。Andew给出了一个检查求导通用的方法,其实就是用小变化来拟合导数,f’(x)≈(f(x+e)-f(x-e))/2*e,其中e是很小的一个值(比如10\^-4)。这个就跟我们图像处理的时候用来求导的方法很像了,因为图像的最小单位是1像素,所以e=1.
\
20140423
今天看week6的应用ML时候遇到高错误率(高代价函数)时候的应对方法。这时候一般我们会有很多想法,比如增减数据,调整bias
term,增删特征。这样乱搞最后效果不一定好,而且耗时,Andrew给出一个诊断方法。
首先将问题分成了high bias和high
variance,从命名方式来理解这两种情况。High
bias就是underfitting,这时候一般bias项都很大,造成其他参数都很小,所以叫high
bias问题;high variance则对应overfitting问题,这时候对于validation
set来说,代价很高,样本在拟合的曲线附近飘得很远,所以叫做high
variance问题。
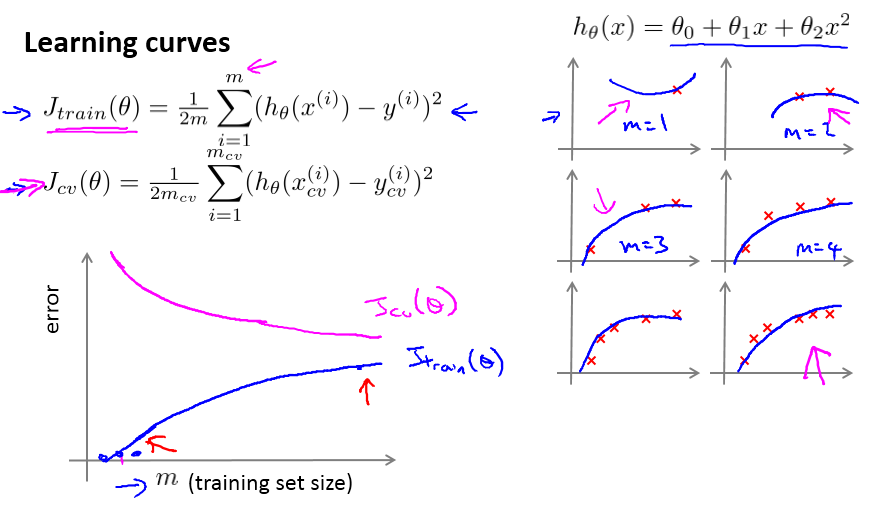
诊断这两个问题,给出了3种图例,其中用learning
curve的诊断效果最后,andrew说他也用这个。
正常的learning curve类似下图,Jtrain逐渐变大,Jcv逐渐变小,最后达到差不多。
High
Bias,或者说underfitting的情况,就是曲线快速聚集到一块,可以看成模型过于简单的情况,这时候增加样本并不能起到作用。因为模型的表达能力有限,所以增加样本没用,这时候应该考虑增加模型的复杂度。
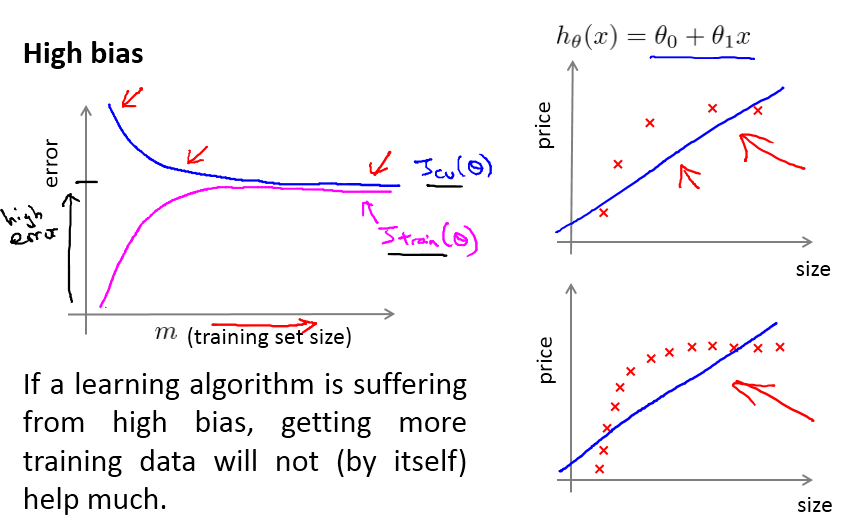
下图是high
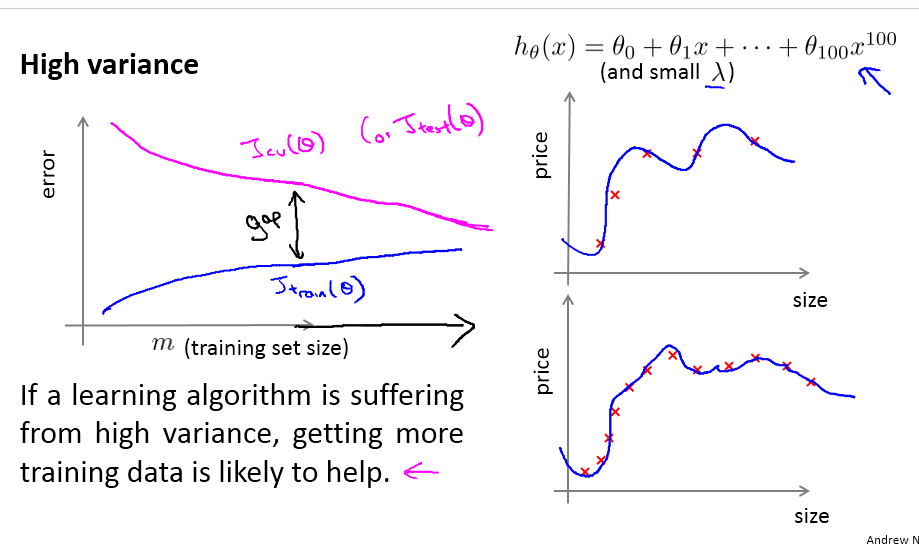
variance问题,也就是overfitting,相反,这里的曲线跟正常时候的唯一差别是两根曲线聚拢的速度过慢。直观地理解成模型过于复杂,需要更多的数据来适应这个模型。
这时候增加样本数据或者是能够解决high
variance的问题的。但注意到有时候是因为模型过于复杂了,或者模型本身已经偏离了正常的假设,这时候增加数据我觉得只是南辕北辙。
所以有了上述的诊断方法后,其实解决方案可以区分成:

也就是看到ML模型效果不好的时候,首先诊断是high variance还是high
bias,这个通过learning curve来得到(如果现在的CNN一次训练那么久就很难知道了,用其他思路,比如直观地看单次的效果来推测,或者看iteration的error curve)。
然后如果是high variance,也就是过拟合,说明模型太复杂,或者数据量不够,这时候就简化模型,或者增加样本;反之,是high bias,也就是低拟合,说明模型太简单,这时候增加数据量就没用(当然减少数据量更加不科学了),这时候可以考虑增加模型的复杂度,或者引入更大的正则项。
\
20140424
今天看week6的下半部分,用实例来说明怎么构建一个好的ML系统。用Anti-spam做例子,我们该不该用stemmed和统一大小写的方法?用什么特征和什么分类器?Andrew认为一开始不用考虑太细致,直接用一天的时间实现一个toy
example般的分类器,然后根据分类器在validation
set上的错误率和分错的样本来寻找改进的思路(更好的特征?更合适的分类器?比如如果分错的邮件中大量包含某个单词,可以认为这个单词是有效的特征)。这个方法的思路是我们要根据实际情况来调整自己的想法,而不是根据“gut”、直觉来选择方法,以至于浪费了时间在错误的方向上。
至于分辨错误率的工具,如果数据偏差很严重,也就是skewed
classes,比如病人中患有癌症的很少,这时候应该用PR值来更加合理地说明检测结果的好坏。如果定下阈值,那么就变成了PR曲线。可以通过实际问题来调整PR曲线,比如要求high
precision,就设置大的阈值等。以及,用F1 score来衡量某对PR值的好坏。
最后也提到了大数据对准确率的影响:
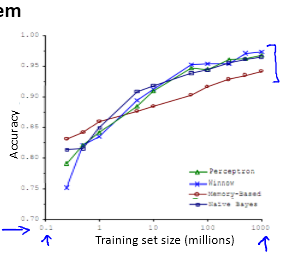
当训练集很大的时候,算法的效果都普遍提升了。Andrew也提到数据不是万能的,当特征不好,模型简单时候,数据就发挥不了它的威力。
\
20140425
昨晚和今天做ex5,有收获,记录下。
Loss function != training error。以linear regression为例子,loss function是training error+正则项。但计算train set和validation set的error时候,就不应该引入正则项了。因为,正则项是用来限制theta的量级的,所以不能算是模型统计出来的结果的error——比如square loss是在欧氏距离下样本真实值和估计值的差别——这个才是train set的error,正则项不属于这里。(说得有点乱,反正,J和Jtrain是不同的计算公式就对了,要理解内涵)
正则项很厉害,至少对于polygon linear regression是的,比如题目要拟合的模型是2次型的(我觉得是),代码中用了8次型的模型来拟合,如果正则项lambda为0(就是没有正则项),那么就会过拟合,如果设置lambda为1,那么就会拟合得很好。(如果根据lambda来进行训练,那么会知道lambda=3时候,模型在这个数据集上表现最好)。正则项在防止过拟合方面真是,当然设置过大的lambda,就会变成欠拟合了。(觉得如果增加样本个数应该也能够防止过拟合问题,如果数据过多,会出现欠拟合问题吗?感觉是不会的。。。这个细想真有意思)
\
20140428
今天开始讲SVM。Andrew用了另外一个角度来讲述,让人惊艳。
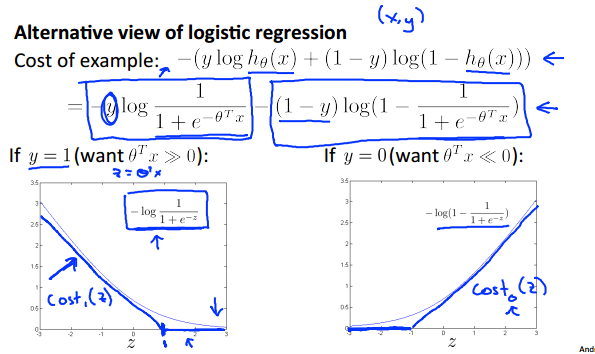
上图描述了SVM和logistic
regression之间的联系。也就是,SVM可以看成修改了cost function和hypothesis的logistic regression。对于cost function,SVM变成了分段函数,在+-1处做了分段,对于hypothesis,SVM也不再是一个连续的概率表示,而是变成了0,1的两个取值的函数。
这样做的目的,是让SVM的优化目标变成了凸函数!!!而logistic regression是非凸的!!(logistic regression的cost也是凸的,如果是MLE的是,而不是LS)这样SVM就没有陷入局部最优的问题了。
另外一个改变是SVM将regular term从λ改成了C,也就是:
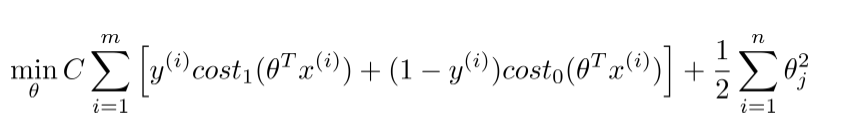
个人理解,这是以为这个是要强调SVM是最大间隔分类器,而这个最大间隔是由后面的theta方求和来决定了。将前面的看成是松弛项。
那么松弛项的作用是什么呢,一般来说,如果样本是线性可分的,那么整个松弛项其实是可以等于0的,也就是可以要求对于训练集每个样本都是正确分开的。不过这回带来一个outline的问题。
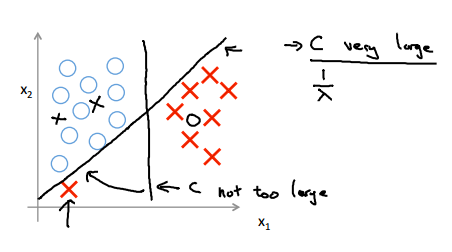
也就是上图中的斜着的那根黑线,如果C设置得很大,也就是对于分错会异常敏感,SVM会趋向于要分对每一个样本。如果将C设置得小一些,那么SVM的容错性会增强,最后拟合出来的黑线是类似竖着的那根的情况。
将C看成是1/λ,上面就好理解了,C大,就是λ小,也就是容易过拟合(对outliner敏感),反过来,C小,λ大,就相对不容易过拟合(但是太小了就会欠拟合,到最后还是一个调参的过程)。
(话说,在我们做分类器的时候,貌似都不强调对样本进行去outliner的处理的,这是why呢?)
\
20140429
之后讲了用核来解决非线性样本的问题,Andrew讲解了Gaussian kernel,讲得很直观,每个样本看成一个地标,每个地标又定义成一个特征(某种高斯距离)。
讲了设置参数的问题,怎么根据实际拟合情况来进行调参。
又及讲了不需要自己去写SVM,用liblinear和libsvm库就很好。
\
20140430
这周说的是非监督的方法,讲了k-mean和PCA。
K-mean没什么特别的,就是随机选k个样本作为初始的中心,然后不断聚集,计算新的中心,直到收敛到一定值。选K方面提到了一个elbow的方法,不过其实大部分情况还是认为指定的。
重点是PCA,明确了几点:
PCA的目标是最小化投影误差,也就是下图的蓝色部分:
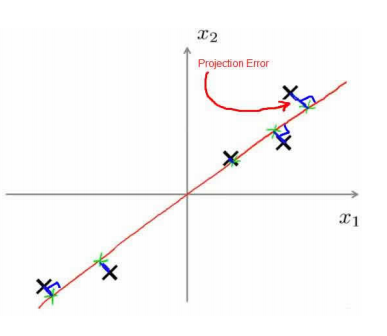
PCA是为了(1)数据压缩(2)可视化。所以一般情况,能用raw data能够获得较好的效果的话,就不应该用PCA。
PCA只是一种投影,而且是不考虑label的投影,所以投影之后,对分类效果未必会有帮助,说不定还有损失
所以,不要在过拟合问题上用PCA,如果数据量不大或者对运算要求不高,不要用PCA。
所以,总的来说,PCA是为了数据压缩来做的,并不能保证能够提升识别率(虽然可以说PCA提取了主要信息,忽略了噪声,这样子,但是其实这个说法还是蛮不靠谱的,谁知道PCA压缩掉的是什么呢)。所以PCA应该是早期为了解决储存和计算性能不足提出来的东西,对于现在的时代来说,应该是没太大用途了。
\
20140505
做了本周的作业,是用Kmean和PCA进行图片数据压缩。
从直观来说,图片压缩的一个方法就是从256灰度中均匀地取16个,然后用最近邻方法将附近的颜色全部聚集在一起。
Kmean可以看成对上述方法的改进,也就是认为均匀地取是不科学的,可能图片本身的颜色分布并不均匀,所以应该选16个最有代表性的,也就是16个k-mean的中心了。
PCA压缩图片的思路跟Kmean不一样,kmean是从灰度聚集的角度入手的,本质上是减少了特征的取值的范围,而PCA是直接操作于特征的,看成将特征投影到某个方向上。
\
201405010
这周开始讲异常检测,这个跟有监督学习很像,不同点在于样本的数量。——异常检测的正样本(异常)很少,也是因为这个原因,导致了常规的有监督学习方法(逻辑回归等)不适用。——一般有监督学习要求正负样本都很多,这样才能估计出它们之间border在什么地方。
异常检测用的是另外的思路,因为正样本不多而负样本很多,所以应该先从负样本中学习出来特征,如果来了一个样本,发现跟负样本不像,那么可以认为是正样本(异常)。
具体方法是选取有高斯分布的特征,通过样本的均值和方差来进行参数估计,求一个联合概率,然后选一个阈值作为分界。
如何选特征:
选带有高斯分布的特征,如果特征不服从高斯分布,但是是单峰的,考虑用log做一个变换。
当发现目前选择的特征不能很好地区分开异常的时候,研究这个出错的样本,来挖掘新的特征。
之后介绍了多高斯分布。
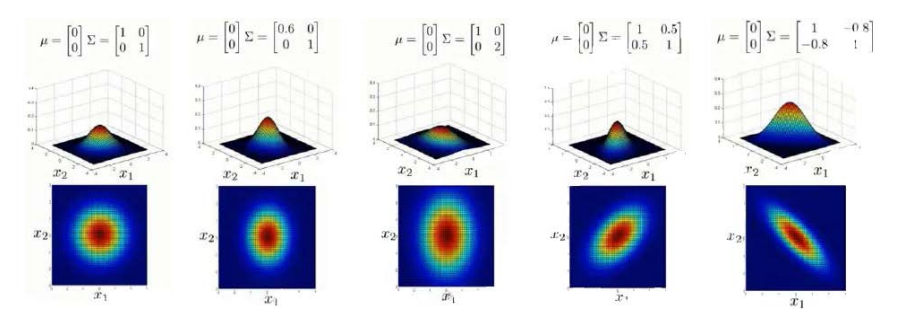
直观地说,使用多高斯分布的话,多了一个协方差上的考虑,也就是,上图2,3用高斯分布就能够比较好地进行拟合,因为之间的相关性为0.而如果像是图4,5的样子,就需要用到多高斯来进行估计了。
多高斯能够自动地capture到不同特征之间的相关性,同时也需要较大的计算代价,用的时候需要权衡一下。
\
20140511
今天将推荐系统的协同过滤算法。协同过滤算法也属于从大数据中自动学习特征的算法。
这个不知道跟CNN有没有联系呢。
以及中间提到了low rank的东西。等做了作业熟悉之后要串联一下这些想法。
\
20140515
今天是最后一周了,没有编程作业。
讲了一些工程上的问题:
BGD->SGD->miniBGD。这里比较有意思的是认为miniBGD比SGD更快,因为miniBGD可以使用vectorize方法来加速。
如何调整学习率α?将数据plot出来,看图说话。
Online Learning,也就是有一个训练的数据流的SGD
MapReduce,用于应对BGD每次迭代计算代价大的问题,直接简单粗暴地Map到N个机器上跑BGD的一部分,然后reduce到一台机器上merge,做到跟BGD一样的效果。
下午将剩下的视频都看完了,说了两件重要的事情:
Augment
dataset:通过轻微的变形来增加数据,注意,通过简单地增加高斯噪声是无效的。
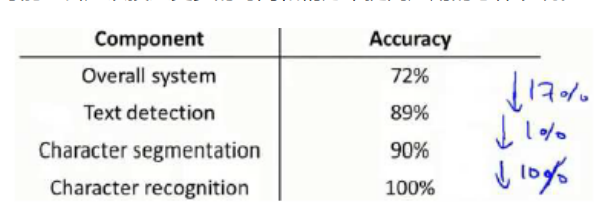
Ceiling
analysis:分析pipeline的每个component,看应该将改进的精力放在什么地方。
于是,到这里,结课了。
每次结课都会有淡淡的忧伤呢。



