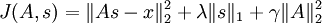20150201 基本概念
基本概念参考了UFLDL。
对于每个输入x,需要找到一组基φ来进行重构,形式化表示为: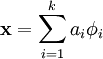
其中φ的维度k是大于x的维度n的,称为over-complete(超完备),它的好处是:
better able to capture structures and patterns inherent in the input data
然后由于超完备,所以对于固定的φ,每个输入是不止一组解的,也就是对于同一个x有多个a,所以这里引入sparse的概念,其实sparse应该算是一个正则项,约束了条件,让大部分a都为0。而sparse的motivation是:
The choice of sparsity as a desired characteristic of our representation of the input data can be motivated by the observation that most sensory data such as natural images may be described as the superposition of a small number of atomic elements such as surfaces or edges.
于是求解输入x的sparse形式,优化目标可以写成下列形式: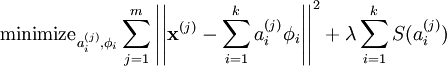
有两项,第一项称为reconstruction term,第二项S(.)称为sparsity penalty。也就是理解成,在一个稀疏的约束下最小化重构误差的问题。
最原始S(.)是0范式,但是不好求解,所以一般会会用1范式,2范式,或者log形式。
另外由于上面式子可以通过缩写a而增大φ得到类似的解,所以需要给φ增加一个上限C,式子就变成了: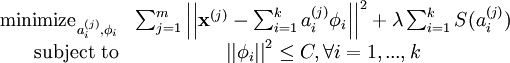
看式子的形式,就跟soft margin下的SVM的loss挺像的了,SVM的是这样子的:
第一项可以看成正则项约束,第二项可以看成是分类误差。
至于怎么求解参数,这份教程简单提了一下,由于需要求解两个未知的参数a和φ,所以需要用到EM-like的方法:
- 对于每个样本优化a
- 对于所有样本优化φ
循环上述两步知道收敛。
而测试时候,需要进行第一步,所以sparse coding在测试时候会比较慢。
sparse coding和sparse autoencoder的联系
依然是参考UFLDL:
http://ufldl.stanford.edu/wiki/index.php/Autoencoders_and_Sparsity
http://ufldl.stanford.edu/wiki/index.php/Sparse_Coding:_Autoencoder_Interpretation
简单的理解sparse autoencoder(SAE),一般的autoencoder的隐藏神经元是比输入输出都要少的,这样能够学习到“压缩”的特征。而SAE刚刚相反,隐藏神经元是大于输入输出的,但是它增加了sparse约束,具体理解跟上面sparse是同一个东西:超正定下但是很多系数为0,也能够学习到输入样本的结构。
而对于SAE的sparse,可以理解成是隐层神经元尽量都不要被激活,所以我们可以通过在loss增加一项正则项来限制隐层神经元的平均激活小于某个特定值ρ,形式化表示为: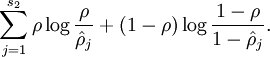
回到sparse coding,它跟SAE有什么关系了,教程只写了一句话:
Sparse coding can be seen as a modification of the sparse autoencoder method in which we try to learn the set of features for some data “directly“. Together with an associated basis for transforming the learned features from the feature space to the data space, we can then reconstruct the data from the learned features.
怎么理解呢,关键应该就是这个directly了。对于SAE的特征学习过程,其实算是indirectly的,因为SAE的特征是在隐神经元的,优化目标其实重构输入,而特征算是在该目标下的一种副产品;另外,个人理解,SAE的稀疏性约束也是比较弱的。另一方面,sparse coding(SC)的目的很明确,就是要学习特征,只不过这些特征能够重构出输入,学习特征是主体,也就是重构反而是学习特征的一种约束。
但其实我觉得本质上还是大同小异的,只是突出了不同的主体,SAE的主体是重构,SC的主体是特征学习,其实从loss来说也都是一项重构项加一项稀疏项,主要是看哪个比较重要咯。
另外,这份教程还给出了SC更加紧凑一个优化形式: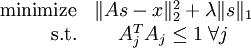
跟上面的式子相比:
本质是一样的,这里的A相当于上面的φ,s相当于上面的a。
为了方便求解,可以把上式的s.t.也统一到式子中: