前言
本文大致分成两大部分,第一部分尝试将本文涉及的分类器统一到神经元类模型中,第二部分阐述卷积神经网络(CNN)的发展简述和目前的相关工作。
本文涉及的分类器(分类方法)有:
- 线性回归
- 逻辑回归(即神经元模型)
- 神经网络(NN)
- 支持向量机(SVM)
- 卷积神经网络(CNN)
从神经元的角度来看,上述分类器都可以看成神经元的一部分或者神经元组成的网络结构。
各分类器简述
逻辑回归
说逻辑回归之前需要简述一下线性回归。
图1 单变量的线性回归
图1中描述了一个单变量的线性回归模型:蓝点代表自变量x的分布——显然x呈现线性分布。于是我们可以用下面的式子对其进行拟合,即我们的目标函数可以写成:
$\hat{y}=\omega x+b$
从单变量到多变量模型,需要将$x$变成向量$\vec{x}$,同时权重$\omega$也需要变成向量$\vec{\omega}$。
$\hat{y}=\vec{\omega}\cdot\vec{x}+b$
而一般线性回归的损失函数会用欧氏距离来进行衡量,即常说的最小二乘法,单个样本的损失函数可以写成:
$\varepsilon = \frac{1}{2}{(y-\hat{y} )}^{2}$
而逻辑回归,可以简单理解成线性回归的结果加上了一个sigmoid函数。
图2 sigmoid 函数图像
从本质上来说,加上sigmoid函数的目的在于能够将函数输出的值域从$(-\infty, \infty)$映射到$(0,1)$之间,于是可以说逻辑回归的输出能够代表一个事件发生的概率。
逻辑分类的目标函数和单样本损失函数是:
$\hat{y}=sigmoid(\vec{w}\cdot\vec{x}+b)$
$\varepsilon=-ylog(\hat{y})-(1-y)log(1-\hat{y})$
这里为何要使用一个复杂的损失函数这构造了一个凸函数,而如果直接使用最小二乘进行定义,损失函数会变成非凸函数。
实际上逻辑回归模型虽然名字带有回归,实际上一般用于二分类问题。即对$\hat{y}$设置一个阈值(一般是0.5),便实现了二分类问题。
而逻辑回归模型的另外一个名称为神经元模型——即我们认为大脑的神经元有着像上述模型一样的结构:一个神经元会根据与它相连的神经元的输入($x$)做出反应,决定自身的激活程度(一般用sigmoid函数衡量激活程度),并将激活后的数值($y$)输出到其他神经元。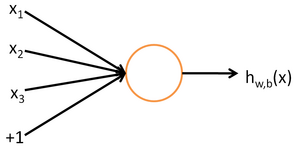
图3 逻辑回归模型,即单个的神经元模型
神经网络(Neural Network,简称NN)
逻辑回归的决策平面是线性的,所以,它一般只能够解决样本是线性可分的情况。
如果样本呈现非线性的时候,我们可以引入多项式回归。
图4 多项式回归解决样本线性不可分的情况,图片来自Andrew Ng的Machine Learning课程的课件
其实,多项式回归也可以看成是线性回归或者逻辑回归的一个特例——将线性回归或者逻辑回归的特征$x$转化为${x}^{2}, {x}^{3}…$等非线性的特征组合,然后对其进行线性的拟合。
多项式回归虽然能够解决非线性问题,但需要人工构造非线性的特征,那么,是否有一种模型,既能够应付样本非线性可分的情况,又同时能够自动构造非线性的特征呢?
答案是有的,这个模型就是神经网络。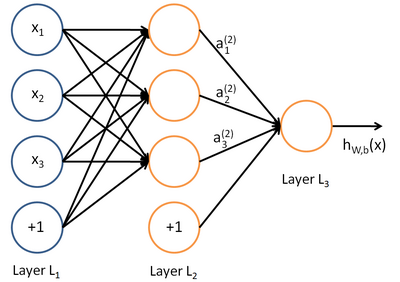
图5 带一个隐层的神经网络模型
如图5所示,每个圆圈都是一个神经元(或者说是一个逻辑回归模型)。所以神经网络可以看成“线性组合-非线性激活函数-线性组合-非线性激活函数…”这样的较为复杂网络结构,它的决策面是复杂的,于是能够适应样本非线性可分的情况。
另一方面,图5中中间一列的橙色神经元构成的层次我们成为隐层。我们认为隐层的神经元对原始特征进行了组合,并提取出来了新的特征,而这个过程是模型在训练过程中自动“学习”出来的。
神经网络的fomulation相对较为复杂,已经超出本文的范围,可参考Standford的深度学习教程
支持向量机(简称SVM)
神经网络的出现一度引起研究热潮,但神经网络有它的缺点:
- 一般来说需要大量的训练样本
- 代价函数边界复杂,非凸,存在多个局部最优值。
- 参数意义模糊,比如隐层的神经元个数应该取多少一直没有定论。
- 浅层神经网络对于特征学习的表达能力有限。
- 深层神经网络的参数繁多,一方面容易导致过拟合问题,另一方面因为训练时间过长而导致不可学习。
于是,在上世纪90年代SVM被提出来后,神经网络一度衰落了。
那么SVM是什么?
SVM,更准确的说是L-SVM,本质上依然是一个线性分类器,SVM的核心思想在于它的分类准则——最大间隔(max margin).
图6 L-SVM本质上是最大分类间隔的线性分类器
同为线性分类器的拓展,逻辑回归和L-SVM有着千丝万缕的关系,Andrew Ng的课件有一张图很清晰地把这两者的代价函数联系起来了(见图7)。
图7 L-SVM和逻辑回归的代价函数对比,SVM的有一个明显的转折点
由于L-SVM是线性分类器,所以不能解决样本线性不可分的问题。于是后来人们引入了核函数的概念,于是得到了K-SVM(K是Kernel的意思)。从本质上讲,核函数是用于将原始特征映射到高维的特征空间中去,并认为在高为特征空间中能够实现线性可分。个人认为,这个跟多项式回归的思想是类似的,只不过核函数涵括的范围更加广,以及形式上更加优雅,使得它能够避免维数灾难。
图8 Kernel能够对特征进行非线性映射(图片from pluskid)
SVM比起神经网络有着以下的优点:
- 代价函数是凸函数,存在全局最优值。
- 能够应付小样本集的情况
- 不容易过拟合,并且有着不错的泛化性能和鲁棒性
- 核函数的引入,解决了非线性问题,同时还避免了维数灾难
更多关于SVM的内容可以参考July的这篇文章:支持向量机通俗导论(理解SVM的三层境界)
然而,其实我们依然可以将SVM看成一种特殊的神经元模型:
- L-SVM本质上跟单神经元(即逻辑回归)模型的最大差别,只是代价函数的不同,所以可以将SVM也理解成一种神经元,只不过它的激活函数不是sigmoid函数,而是SVM独有的一种激活函数的定义方法。
- K-SVM只是比起L-SVM多了一个负责用于非线性变换的核函数,这个跟神经网络的隐层的思想也是一脉相承的。所以K-SVM实际上是两层的神经元网络结构:第一层负责非线性变换,第二层负责回归。
- 《基于核函数的SVM机与三层前向神经网络的关系》一文中,认为这两者从表达性来说是等价的。(注:这里的“三层前向神经网络”实际上是带一个隐层的神经网络,说是三层是因为它把网络的输入也看成一个层。)
卷积神经网络
近年来,神经网络又重新兴盛起来了。尤以“卷积神经网络”为其代表。于是本文下面的篇幅主要围绕卷积神经网络进行展开。
生物学基础
引自Deep Learning(深度学习)学习笔记整理系列之(七)。
1962年Hubel和Wiesel通过对猫视觉皮层细胞的研究,提出了感受野(receptive field)的概念,1984年日本学者Fukushima基于感受野概念提出的神经认知机(neocognitron)可以看作是卷积神经网络的第一个实现网络,也是感受野概念在人工神经网络领域的首次应用。神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有位移或轻微变形的时候,也能完成识别。
通常神经认知机包含两类神经元,即承担特征抽取的S-元和抗变形的C-元。S-元中涉及两个重要参数,即感受野与阈值参数,前者确定输入连接的数目,后者则控制对特征子模式的反应程度。许多学者一直致力于提高神经认知机的性能的研究:在传统的神经认知机中,每个S-元的感光区中由C-元带来的视觉模糊量呈正态分布。如果感光区的边缘所产生的模糊效果要比中央来得大,S-元将会接受这种非正态模糊所导致的更大的变形容忍性。我们希望得到的是,训练模式与变形刺激模式在感受野的边缘与其中心所产生的效果之间的差异变得越来越大。为了有效地形成这种非正态模糊,Fukushima提出了带双C-元层的改进型神经认知机。
基本的网络结构
一个较为出名的CNN结构为LeNet5,它的demo可以参看这个网站。图9是LeNet的结构示意图。
图9 LeNet5的网络结构示意图

图中的Convolutions对应了上一段说的S-元,Subsampling对应了上一段中说的C-元。
对于Convolution层的每个神经元,它们的权值都是共享的,这样做的好处是大大减少了神经网络的参数个数。
对于Sampling层的每个神经元,它们是上一层Convolution层的局部范围的均值(或者最大值),能够有效地提供局部的平移和旋转不变性。
为何神经网络重新兴起?
卷积神经网络属于一种深度的神经网络,如上文所说,深度神经网络在之前是不可计算的,主要是由于网络层次变深后会导致下面问题:
- 由于网络参数增多,导致了严重的过拟合现象
- 在训练过程中,对深度网络使用BP算法传播时候梯度迅速减少,导致前面的网络得不到训练,网络难以收敛。
而这两个问题在目前都得到了较好的解决:
- 共享权值:即上文提到的卷积层的卷积核权值共享,大大减少了网络中参数的数量级。
- 加大数据量:一个是通过众包的方式来增加样本的量级,比如,目前ImageNet已经有了120万的带标注的图片数据。另一个是通过对已有的样本进行随机截取、局部扰动、小角度扭动等方法,来倍增已有的样本数。
- 改变激活函数:使用ReLU)作为激活函数,由于ReLU的导数对于正数输入来说恒为1,能够很好地将梯度传到位于前面的网络当中。
- Dropout机制:Hinton在2012提出了Dropout机制,能够在训练过程中将通过随机禁止一半的神经元被修改,避免了过拟合的现象。
- GPU编程:使用GPU进行运算,比起CPU时代运算性能有了数量级的提升。
上述问题得到有效解决后,神经网络的优势就得到充分的显现了:
- 复杂模型带来的强大的表达能力
- 有监督的自动特征提取
于是神经网络能够得到重新兴起,也就可以解释了。下文会选取一些样例来说明神经网络的强大之处。
CNN样例1 AlexNet
在ImageNet举办的大规模图像识别比赛ILSVRC2012中分类比赛中,Hinton的学生Alex搭建了一个8层的CNN,最终top-5的漏报率是16%,抛离而第二名的27%整整有11个百分点。
图10 AlexNet的CNN结构,包括5个卷积层,和3个全连接层,最后一个softmax分类器
这个网络中用到的技术有:
- ReLU激活函数
- 多GPU编程
- 局部正则化(Local Response Normalization)
- 重叠的下采样(Overlapping Pooling)
- 通过随机截取和PCA来增加数据
- Dropout
CNN样例2 deconvnet
在下一年的比赛ILSVRC2013中,在同样的数据集同样的任务下,Matthew进一步将漏报率降到了11%。他使用了一个被命名为“Deconvolutional Network”(简称deconvnet)的技术。
Matthew的核心工作在于尝试将CNN学习出来的特征映射回原图片,来对每个卷积层最具有判别性的部分实现可视化——也就是,观察CNN在卷积层中学习到了什么。
图11 deconvnet的思想是将网络的输出还原成输入
CNN样例3 DeepPose
DeepPose的贡献在于它对CNN使用了级联的思想:首先,可以用第一层CNN大致定位出人物的关节位置,然后使用反复使用第二层神经网络对第一层网络进行微调,以达到精细定位的目的。
从另外一个角度,这个工作也说明了,CNN不仅能够应付分类问题,也能够应付定位的问题。
图12 DeepPose通过级联地使用CNN来达到精细定位关节的位置
CNN样例4 CNN vs 人工特征
CNN Features off-the-shelf: an Astounding Baseline for Recognition
该工作旨在验证CNN提取出来的特征是否有效,于是作者做了这样的一个实验:将在ILSVRC2013的分类+定位比赛中获胜的OverFeat团队使用CNN提取出来的特征,加上一个L-SVM后构成了一个分类器,去跟各个物体分类的数据集上目前最好(state-of-the-art)的方法进行比较,结果几乎取得了全面的优胜。
总结
本文对数个分类器模型进行了介绍,并尝试统一到神经元网络模型的框架之中。
神经元网络模型的发展一直发生停滞,只是在中途有着不同的发展方向和重点。
神经元网络模型是个极其有效的模型,近年来由于样本数量和计算性能都得到了几何量级的提高,CNN这一深度框架得以发挥它的优势,在计算机视觉的数个领域都取得了不菲的成就。
目前来说,对CNN本身的研究还不够深入,CNN效果虽然优秀,但对于我们来说依然是一个黑盒子。弄清楚这个黑盒子的构造,从而更好地去改进它,会是一个相当重要的工作。
参考
- Machine Learning@Coursera
- UFLDL Tutorial
- 支持向量机通俗导论(理解SVM的三层境界)
- 支持向量机系列 from pluskid
- 基于核函数的SVM机与三层前向神经网络的关系,张铃,计算机学报,vol.25,No.7,July 2012
- Deep Learning(深度学习)学习笔记整理系列之(七)
- ImageNet Classification with Deep Convolutional Neural Networks,Alex Krizhevsky.etc,NIPS2012
- Visualizing and Understanding Convolutional Networks,Matthew D. Zeiler,arXiv:1311.2901v3 [cs.CV] 28 Nov 2013
- DeepPose: Human Pose Estimation via Deep Neural Networks,arXiv:1312.4659v1 [cs.CV] 17 Dec 2013
- CNN Features off-the-shelf: an Astounding Baseline for Recognition,arXiv:1403.6382v3 [cs.CV] 12 May 2014



